Oletko vastuussa asiakaspalautteiden käsittelystä tai johtamisesta? Tai oletko johtaja, joka tunnistaa datan merkityksen päätöksenteossa? Tämä kirjoitus on juuri sinulle.
Olet saattanut törmätä tilanteeseen, jossa sinulla on kerättyjä asiakaspalautteita ja olet käyttänyt valmista sovellusta tekstin ryhmittelyyn, mutta lopputulos on jättänyt toivomisen varaa. Tulokset ovat olleet kenties epätarkkoja tai ne eivät ole palvelleet organisaatiosi yksilöllisiä tarpeita.
Usein oletuksena saattaakin olla, että eivätkös AI-ratkaisut hoida tämän automaattisesti? Näin asia ei valitettavasti ole. Tämä kirjoitus kertoo, millaisia asioita asiakaspalautteita käsittelevän henkilön tulisi ottaa huomioon ja mihin ihmistä tässä työssä edelleen tarvitaan, jotta analyysi tuottaisi hyödyllistä tietoa organisaatiollesi.

One-size-fits-all ei päde vapaamuotoisen tekstin ryhmittelyssä
Asiakaskyselyihin liittyvissä toimeksiannoissa halutaan usein ryhmitellä käyttäjien omin sanoin kirjoittamia palautteita. Tämä vapaa teksti tarjoaa tarkempaa tietoa käyttökokemuksista, kuin valmiiksi asetetut aihekohtaiset kysymykset, joihin vastataan myöntävästi tai kieltävästi. Palautteiden ansiosta saadaankin tärkeää tietoa asiakasta askarruttavista aiheista, joita seuraamalla pystytään toimintoja keskittämään ja ajan suhteen havainnoimaan, onko korjaavista toimenpiteistä ollut apua.
On tärkeää pohtia, millaisilla ratkaisuilla asiakaspalautteista voi saada mahdollisimman yksiselitteisiä tekstiryhmiä. Mahdolliset toimenpiteet tekstin ryhmittelyssä ovat toisaalta jo vakiintuneita, mutta se, mitä niistä valitaan, riippuu siitä, millaista tekstiä tullaan ryhmittelemään. One-size-fits-all ei siis päde. Tähän blogitekstiin sisältyy teknistä tietoa, mutta pyrin tietoisesti käyttämään kuvakielisiä ilmaisuja niitä esitellessäni ja keskityn olennaisiin, yksinkertaisiin perusmenetelmiin. Kirjoituksen luettuasi ymmärrät toivottavasti tekstin ryhmittelyyn liittyviä perusluonteisia tekniikoita paremmin (mm. vektorisointi sekä ohjattu että ohjaamaton ryhmittely), joiden valinta vaikuttaa merkittävästi ryhmittelyn laatuun.
Tekoäly kaipaa ihmisälyä toimiakseen
Olet ehkä kuullut nykyisten käsitteiden kuten Large Language Model (LLM) tai chat-tyylisten ylemmän tason palveluiden kyvykkyyksistä käsitellä millaista tekstiä hyvänsä. Toisaalta taas, sinulla saattaa olla kokemusta kaupallisten, tekstiaineistojen käsittelyyn tehtyjen sovellusten ominaisuuksista. On kuitenkin tärkeää tiedostaa, että kaiken tekstin ryhmittelyn taustalla on perinteisiä menetelmiä, joista pääasiallisimpia haluan tämän kirjoituksen avulla kuvata.
Käsittelen ensimmäisenä, miten ryhmät saadaan muodostettua ohjaamattomasti, johon kuuluu olennaisesti tekstin esikäsittely sekä vektoriesityksen muodostaminen, koska algoritmit käsittelevät tekstiäkin numeroina. Tämä on olennainen vaihe ryhmien muodostamiseen. Ohjaamattoman ryhmittelyn tarkkuus ei ole välttämättä halutun kaltainen. Se myös tuottaa anonyymejä, nimettömiä tekstityhmiä – siksi eräänä lisäkeinona on rikastaa palauteaineistoa jo antovaiheessa. Käyn läpi myös tekstin ennalta määriteltyjen kategorioiden määrittelyn ja sen myötä ohjatun ryhmittelyn, jonka avulla saavutetaan tarkempi tulos sekä nimetyt aihealueet.
Esikäsittely on tiedon siistimistä
Tietokoneet tulkitsevat tekstiä merkkijonoina. Tämä on eräs syy siihen, miksi tarvitsemme esikäsittelyä. Yksinkertaisimmillaan tekstiä halutaan puhdistaa erikoismerkeistä (@, €, $, hymiöt/muut emojit, yms.). Sanojen taivutusmuotojen poisto, eli perusmuodoiksi kääntäminen on toinen yleinen menetelmä, joilla suuri määrä tekstiä saadaan yhtenäistettyä, ettei algoritmit tulkitsisivat merkkijonoina kuvatut käsitteet yksiselitteisemmin. Teksti sisältää myös suuria määriä sulkusanoja (ja, tai, mutta, jne.), nämä ovat myös tarpeenmukaista poistaa, jotta tekstistä korostuisi asiasisältö.
Vektoriesityksellä havainnollistat asiayhteyksiä
Tekstin vektoriesitys on tärkeää siksi, että sen avulla teksti voidaan kuvata pisteinä sana-avaruudessa, jolloin samaa tarkoittava teksti on kuvainnollisesti sanoen lähempänä tuossa avaruudessa. Ryhmittelyn ydin on oikeastaan tavassa, miten vektorit määritellään, joka taas johtaa siihen, miten laadukkaita ryhmät ovat. Vektoriesitykset voidaan jakaa karkeasti perinteisiin ja nykyisiin ns. piilomalleihin, jotka kykenevät mallintamaan sanojen semanttisia yhteyksiä, kuten että manse tarkoittaa Tamperetta.
Perinteisten esitysten kannalta voidaan yksinkertaistaa asiaa siten, että ne eivät ota kantaa sanojen järjestykseen ja niillä kuvataankin vain mitä sanoja aineistossa on. Yksinkertaisena esimerkkinä kaksi lausetta ja neljä sanaa sisältävä aineisto: "tämä on hienoa"=[1, 1, 1, 0] ja "tämä on mahtavaa"=[1, 1, 0, 1]. Sana siis esiintyy tai ei esiinny ja sen määrä on aineistossa se ja se. Vektorin arvojen muodostamiseen on useita eri menetelmiä. Usein halutaankin painottaa harvemmin esiintyviä sanoja, koska useimmiten esiintyvät ovat täytesanoja, joilla on tuota harvoin itse asiaan liittyvää merkitystä nääs. Kun sanoja on paljon, usein jopa kymmeniä tuhansia, vektorit ovat siten pitkiä, mutta pitkien ilmaisuvoima ei kuitenkaan ole suurempi.
Piilomallien perusideana on, että vektorien ulottuvuudet kuvaisivat tekstissä esiintyviä käsitteitä ja niiden tarkoitus onkin kuvata asiayhteyksiä. Menetelmä tunnetaan myös nimellä "Word embedding", jolloin vektorit ovat osana eri tarkoituksia varten opetettuja malleja. Tarkoitukset voivat olla esim. kielen käännös, jälkimmäisen sanan ennustaminen, tekstistä puuttuvien sanojen ennustaminen, jne. Malleja on lukemattomia, mutta nykyaikaiset menetelmät ovat yleensä neuroverkkoihin perustuvien transformer-arkkitehtuurien hyödyntämiä. Näitä ovat mm. Generative Pretrained Transformer (GPT) mallit, jotka ovat suurempia vektoriesityksiltään tai niiden vanhemmat, vektoriesityksiltään pienemmät esiasteet kuten BERT tai LaBSE.
Nykyaikaiset mallit ja niiden sisältämät vektorit oppivat tekstin semanttisia rakenteita. Huomattavaa kuitenkin on, että käytetyllä opetusaineistolla on merkitystä. Jos halutaan luokitella lakitekstiä, opetusaineistoksi ei sovellu arkikieltä sisältävä aineisto.
Klusterointi on ohjaamatonta ryhmittelyä
Kaikkein yksinkertaisin tapa ryhmitellä tekstiä on käyttää klusterointia, eli matemaattista menetelmää, jonka avulla numeeriset vektoriesitykset saadaan jaettua omiin ryhmiin numeeristen arvojen perusteella. Numeroavaruudessa lähellä toisiaan olevat esitykset muodostavat siis luonnollisia ryhmiä. Tässä tapauksessa ei ole tarve kuvata ryhmittelyä seikkaperäisemmin, mutta voitaneen kuvitella, että miten teksti esitetään numeerisina vektoreina vaikuttaa suoraan siihen, miten hyvin samankaltaisia aiheita sisältävät tekstit voidaan jakaa selkeisiin ryhmiin.
Ohjattu tekstin ryhmitteleminen
Edellä kuvasin ohjaamatonta tapaa ryhmitellä tekstiä. Tapa on käytössä silloin, kun tekstin sisältöä ei tiedetä, tai samankaltaista tekstiä halutaan ryhmitellä ennalta automaattisesti jäljenpää analysointia varten. Tällöin kuitenkin saavutetaan anonyymejä ryhmiä, joita on vain ennalta määrätty lukumäärä. Ryhmiä voi toki analysoida listaamalla sanojen esiintymiskertoja, usein yhdessä esiintyviä sanapareja tai muita ryhmiä, ja niin edelleen.
Asiakaspalautteen tai muun asiatekstin analysoimiseksi on toivottavaa listata ennalta määrättyjä aiheita ja kuvata lukumääriä, miten paljon tekstiä kuhunkin aiheeseen on annettu, jos halutaan esim. seurata palveluun XYZ annetun palautteen määrää.
Menetelmää kutsutaan ohjatuksi oppimiseksi. Tällöin tulee halutut aiheet, eli kategoriat nimetä ja esitellä kutakin aihetta vastaavat esimerkkitekstit. Näitä aihe-esimerkkipareja käytetään siten opettamaan malli, joka osaa kertoa, mitä aihetta jäljempänä saatu uusi teksti kuvaa.
Usein ajatellaankin, että tämä tapahtuisi automaattisesti. Näin ei kuitenkaan ole, vaan mallit joudutaan opettamaan ja manuaalityö kategorioitten sekä esimerkkitekstin osalta tekemään. Modernit chat-palvelut sekä LLM:t ovat myös opetettu esimerkkiaineistolla.
Valmiita malleja on täten olemassa. Mutta, on huomattavaa, että valmiit mallit ovat yleensä opetettu käyttämällä yleisiä asiatekstejä (Wikipedia, sähköiset kirjat, jne.) eivätkä siten sovellu domain käyttöön teollisuuden, julkishallinnon, tai minkä tahansa muun rajatumman aihepiirin tekstin luokitteluun.
Esimerkkikiekko päätyyn ja joukkue perään
Loin CxO Industry –tapahtumaan demon, jossa käytin valmiita kirjastoja wordcloudin sekä aihealuejaon toteutuksessa. Ajatuksena olikin havainnollistaa, missä ihmisen työtä kuitenkin tarvitaan ja mikä tekoälykomponenttien rooli vastaavanlaisessa työssä on.
Sovellus tallensi lavan esityksiä streamin kautta, teki puheentunnistuksen ja muodosti alla esitellyn pilven usein esiintyvien sanojen suhteen sekä tilastoi puhutut aihealueet käyttäen Hugging Facen kirjastoa, jonka käyttämä malli oli Walesilaisen Cardiff yliopiston opettama, jossa aihealueet ovat korkean tason yleistyksiä.
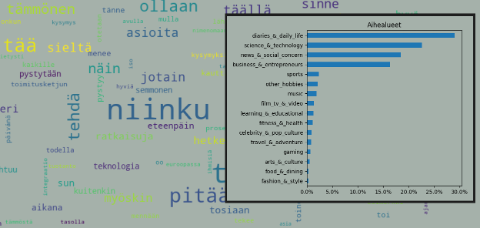
Sovellus esikäsitteli tekstiä poistamalla sulkusanat (ja, tai, …). Voidaan kuitenkin huomata, että suurin osa puhutussa tekstissä on täytesanoja, eikä yksinkertainen sanojen tilastointi korosta täten sisältöä. Menetelmiä sanojen painotukseen, jotka pienentäisivät kaikkein suosituimpien sanojen arvoa valittu moduuli ei käyttänyt, kuten ei myöskään edellä mainittua kollokaatioanalyysiä. Aihealuejaon suhteen käy ilmi, että jos halutaan tarkempaa tekstin kategorisointia, tarvitaan tarkoitukseen sopivaa ja kyseessä olevaa aihetta varten opetettua mallia.
Milloin käyttää ohjaamatonta ja milloin ohjattua tekstin luokittelua?
Luit juuri kuvauksen ohjaamattomaan ja ohjattuun tekstin luokitteluun liittyvistä perusominaisuuksista. Oleellista asiakaskyselyihin liittyvissä tehtävänannoissa on se, että ne sisältävät aihetekstiä, joiden käsitteet liittyvät toimeksiantajan liiketoimintaan. Jotta saataisiin kattava kuva mitä aiheita palautteisiin liittyy, on usein käytettävä ennalta määriteltyjä aiheita ja sovellettava ohjattua oppimista. Tällöin nimettyjä aiheita ja niitä koskevien palauteiden määriä voidaan seurata.
Ohjaamatonta oppimista käytetään, kun aiheita ei tiedetä, tai kun halutaan automatisoida tekstin ryhmittely ohjattua käyttötarkoitusta varten helpottamaan tekstiesimerkkien määrittelyä. Toki, jos manuaalityötä ja ennalta määriteltyjä aiheita ei koeta tarpeelliseksi, voidaan käyttää täysin automatisoitua ohjaamatonta tapaa ryhmittelyyn. Tällöin ryhmiä voidaan edelleen tiivistää eri menetelmin, jotta niiden sisältö voitaisiin kuvata lyhyesti. Sanaesiintymien tilastointia tai kollokaatio analyysiä, eli usein esiintyvien sanaryhmien tunnistamista, tai muuta vastaavaa, voidaan käyttää tiivistämään saatuja anonyymejä ryhmiä.
Liikkeelle on lähdettävä peruskysymyksestä
Toivottavasti kirjoitus selvensi tekstin ryhmittelyyn liittyviä haasteita. Monissa tekemissämme projekteissa on tullut ilmi, että peruskysymys useimmiten on löytää tekstiaineistosta samankaltaisia aiheita päätöksenteon tueksi. Tämä kysymys on oleellinen riippumatta siitä, käytetäänkö kaupallista, räätälöityä tai ehkä PoC-tason sovellusta. “Ongelmana” on usein se itse teksti ja domainiin liittyvä aiheteksti vaatii useimmiten perehtymistä itse tekstiaineistoon, joka on edellytys sille, että oikea menetelmä ja lähestymistapa voidaan valita, jotta tehtävänannossa esitettyihin kysymyksiin osattaisiin vastata mahdollisimman hyvin.
Tässä välissä onkin mainittava, että nykyisin on olemassa menetelmiä, jossa voidaan hyödyntää uusimpia kielimalleja, joita ei tarvitsekaan kouluttaa halutulla aihetekstillä. Näiden ratkaisujen päälle voidaan tarjota luonnollista kieltä käyttävä chat-rajapinta, käyttäjän saadessa selkokielisen vastauksen. Mutta, nämä ovatkin toinen tarina, joista puhumme tuonnempana, mutta joita teknologioita voimme jo käyttää nykyisissä toimeksiannoissamme.
Ryhmittelyyn liittyvillä muilla toiveilla, kuten tilastointiin muiden piirteiden suhteen on eroja riippuen käyttötarkoituksesta. Tällaisia piirteitä voisivat esimerkiksi olla palautetta antaneiden ikäryhmät, organisaatiot, ja niin edelleen. Tekstianalyysi kuuluu onneksi osaamisalueeseemme ja olisi mielenkiintoista kuulla teidän tavoitteestanne muun muassa palauteanalyysin suhteen.
Ehkä voimme auttaa teitä tässä työssä?

